Filtering 90% of blank wildife photos for a better UX
Our community wildlife classification/identification project is live at rangers.urbanrivers.org.
Using AI, we are massively fixing the boring part.
Introduction
Over the first 9 months, volunteers have labeled just over 60k images in our database (oct’24-jun’25).
Of these, ~46k were labeled blank (grass/leaves/wind sets off the sensor) and ~14k were labeled as containing at least one animal.
A human labeling rate of about 6.7k images per month with 77% of those being blanks.
Extrapolating that number to the 200k+ images currently needing labels and blanks being 77-84%.. we could be looking at 154-168k blank images (😴) that should take another 21-25 months (~2 years) to complete.
This post will describe how we’re making use of the speciesnet (and megadetector) results from the first pass through our dataset.
Project Steps so far:
- Generate Speciesnet Inference on dev and then production images
- Try to fine-tune an imagenet model for a site specific classification system with limited data
- Explore results, classifications and confusion matrices
- Process speciesnet inferences and append results to MongoDB records
- Compare Humans vs AI in Tableau
- (This post) - Implement aiResults filters for less human labeling fatigue.
Adding a filter based on SpeciesNet detections
Users have to identify animals - but most images are blank.
SpeciesNet (based on EfficientNet) uses MegaDetector (based on YOLOv5) to detect objects in images, classify their probability as human, animal, vehicle - and draw bounding boxes around the images.
When we ran speciesnet through our 200k+ images - approximately 90 % of our images showed up as total blanks (an confAnimal of 0.0). Based on initial validation of speciesnet vs human labels - this is likely at least 80% true blanks. So, while there is an argument for observed blanks vs passive assumed blanks, this represents an enormous bulk of VERY boring images to look at.
Step 1. Process speciesnet inferences for MongoDB upload
Just like exploring the data in our last post - we open the speciesnet inference json and extract detection confidences for each image. See the parsing script here: mongo-ur-utils/ai_results/ai_detection_parser.py
The confidences are then uploaded to mongodb through some python script. See the upload script here: mongo-ur-utils/ai_results/ai_mongo_operations.py
Step 2. Building a Filter in an existing Repo
Enter Jules - google’s async coding agent hero to the rescue. I’m not a node developer, but I do have a very good idea of what we want and how to test the systems. After connecting to the site repo, I presented Jules with the following prompt:
I've added some aiResults data to my mongodb and want to be able to add filters
while looking through images on the observations site for the app.
First, by default, if confHuman is anything above 0.50 we should not be showing those images
- please identify how we could do that.
Second, we want to provide a slider on the existing filters to select
a "max confidence blank" value - ie if the value is 0.8,
then only images where confBlank is below 0.8 will show up.
Here's the structure of one of the mongo records for example:
{'_id': ObjectId('671a925b731cf4b5c4fd2203'),
'mediaID': 'fb04201b6417ea917fdd24e1a7415d8a',
'imageHash':
...continues...
I’ll be honest - this took several hours of back and forth - but most of that was fine tuning and tweaking the behavior. So, it’s not automatic, but the structure and prototyping speed from concept to ideation/iteration is unmatched. Ultimately we restructured the filter to work on confAnimal because pointing at confBlank was confusing, and caused some strange behaviors when the max confidence was actually human or vehicle.
In the end, a fully functional modification to the already existing get request was created.
Here’s what it looks like -
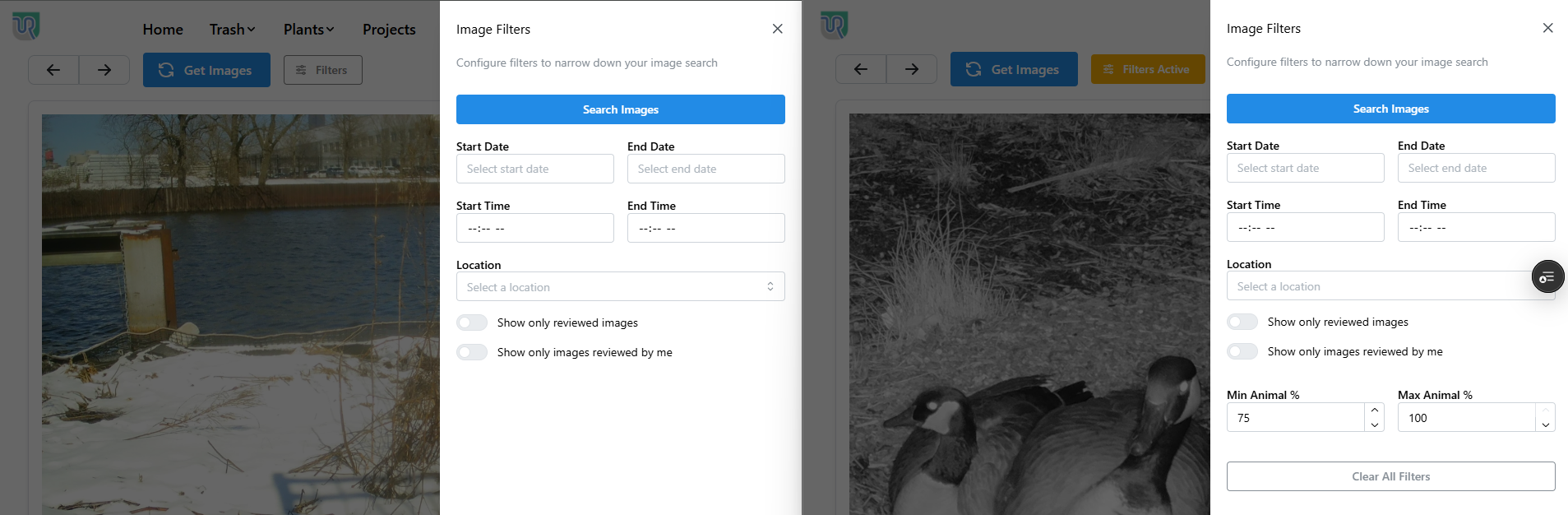
Based on previous analysis, we chose to show only images with at least 75% chance of an animal as the first default.
The PR can be seen here and if the PR preview server is still live when reading this - go here.
If not - the rangers site is public and available here.
Next Steps:
We now have object detection, our own classification model, and effective human labeling filters. The next stages will involve reinforcment model training: Using complementary approaches for curating and fine tuning models.
Without any real plans or order yet:
- Using speciesnet inference to source images likely to have animals (done)
- Using human labels to source new confirmed classficiations (in progress)
- Using early imagenet/pytorch classification to source additional classified images (todo)
- Confirming sourced images and repetitive rounds of cleaning + fine tuning (todo)
— future work scope — - Building multi-class systems
- Refining object detection to include counts.
- Rolling out video classification.