Comparing AI computer vision with Human Labeling
We have AI results and volunteer contributed human labels for approximately 60,000 images.
This post explores the relationships between human error and ai errors.
Project Steps so far:
- Generate Speciesnet Inference on dev and then production images
- Try to fine-tune an imagenet model for a site specific classification system with limited data
- Explore results, classifications and confusion matrices
- (linked below) Process speciesnet inferences and append results to MongoDB records
- (This post) Compare Humans vs AI in Tableau
Process speciesnet inferences for MongoDB upload
Essentially, we open the speciesnet inference json and extract detection confidences for each image.
For each animal and human detections we find the maximum - then for the max between both, we infer the blank probability.
Vehicles are default lumped into blanks and we have useful features for eventual filtering parameters.
See the code in this repo: mongo-ur-utils
Kaggle notebook for ETL
Given that the MongoDB now has aiResults for all 200k+ images and human labels for around 60k, we can extract the relevant fields from each image (linked by a mediaID) and discover the relationships between them. For example:
- If we were to implement a filter that removed low confidence animal detections, how many false negatives (ai missed the animal) would we be overlooking?
- How many images in a high ai animal detection confidence have we labeled already?
- What portion of these have 3 observations?
- What default filter settings might be affecting this?
First we grab the relevant fields - both speciesConsensus and aiResults are arrays/dictionaries so we will have to further query those.
query = {
"speciesConsensus.0": {"$exists": True},
"aiResults.0": {"$exists": True}
} # records that have both only - drops nulls or missing
projection = {
"_id": 0,
"mediaID": 1,
"publicURL": 1,
"speciesConsensus": 1,
"aiResults": 1
}
all_obs = list(collection.find(query, projection))
This returns a observation json obs_json which we further flatten with:
# flatten list init
flat_rows = []
# for each mediaID/item in obs_json
for item in obs_json:
media_id = item.get('mediaID')
url = item.get('publicURL')
# Use first entry of speciesConsensus and aiResults
# Noting that speciesConsensus[0] is generally the animal consensus if there is one
# We could filter the results before extracting - but it's true enough for right now
consensus = item.get('speciesConsensus', [{}])[0]
ai = item.get('aiResults', [{}])[0]
flat_rows.append({
'mediaID': media_id,
'publicURL': url,
'observationType': consensus.get('observationType'),
'scientificName': consensus.get('scientificName'),
'observationCount': consensus.get('observationCount'),
'confBlank': ai.get('confBlank'),
'confHuman': ai.get('confHuman'),
'confAnimal': ai.get('confAnimal'),
})
flat_rows can now be condensed into a dataframe and exported from here for further analysis.
df = pd.DataFrame(flat_rows)

Kaggle notebook found here.
Tableau for EDA
Exploring the dataset further, I built a dashboard to visualize things like:
- What do images look like where the ai thought there was an animal but people marked blank? (human false negatives)

There are human false negatives that ai would not have missed. This probably happens by mistake when people are reviewing multiple images with some lag between load times. There was no filter on number of observations - so some of the human false negatives would eventually bubble up as more observations are made on the same image by multiple people.
- What do images look like where the ai thought it was blank, but people marked an animal? (ai false negatives)

There clearly are some images that people can see better than ai - but also some human false positives.
- Are there any particular species that the ai has a hard time detecting? (ai false negatives by class)
- This portion of the table looks at the 50% probability odds with the aiResults filter with at least 100 images labeled.
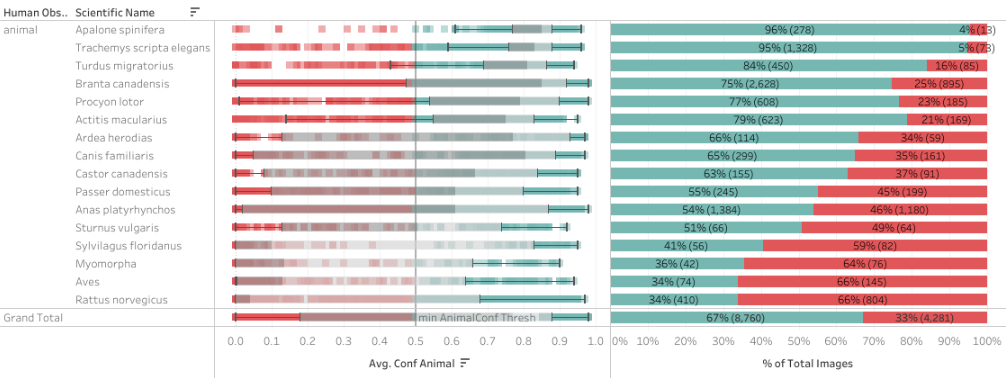
The worst losses happen in rattus norvegicus (brown rats), Aves (unspecified bird), Myomorpha (unspecified rodent), and Sylvilagus floridanus (rabbits). Keeping in mind these are not ‘deleted’ images but instead images that could be ignored in preference of accelerating others.
- What threshold would remove the most true blanks without accientally removing images with animal in them? (ai sensitivity)
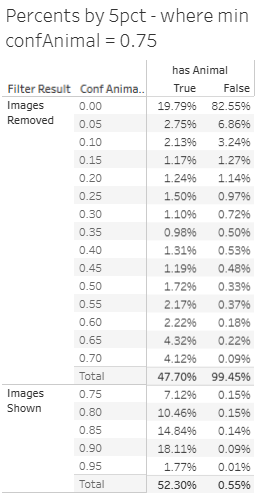
- These tables show the cumulative percentage where human labeled an animal (has animal) vs 5% bins of SpeciesNet confidence of an animal detection.
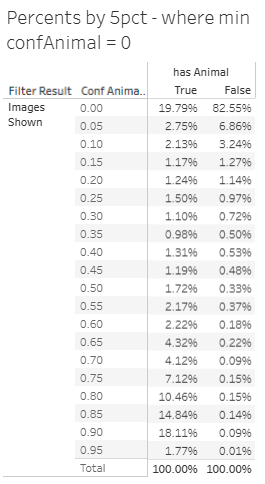
Already at just 5% probability of an animal - there’s an effective removal of 82.55% of blank images labeled by humans that would be filtered out.
That’s huge! We’re aiming at focusing on the most likely images with animals in them by setting a filter of 75% minimum confAnimal default - at that level that would remove 99.45% of blanks people are labeling - true blanks where nothing was in the image.
At 75% - this does come at a cost of up to 47.7% of the images people have labeld as containing an animal (some false positives) would be initially filtered out. At 5% - that false negative cost drops to 19.79% in our sample. We’ll use these statistics to determine how to apply a filter to the user experience on rangers.urbanrivers.com.
.
Here’s a link to the dashboard, also embedded below.