Learning NLP through steam game reviews
There are over 100,000 games in the Steam catalog and 132 million monthly active users (MAUs). Users are allowed to leave reviews and votes (thumbs up or thumbs down) about games after purchasing.
It would be interesting if AI could predict the vote based on the review text - let’s see what happens!
Introduction
This started out as a want to understand more about ML sentiment analysis - but by the time I was introduced to NLP, the context was around fine-tuning a model to be able to predict / minimize / maximize a target statistic. So, following the fastai book - and peaking at the data available through various Steam APIs. This project focused on predicting the thumbs-up vs. thumbs-down binary based on the user’s review
Downloading reviews through APIs
I found two APIs for this project:
- A public API sourced through steamspy.com
- A private API sourced directly through the Steam API that requires a user API Key.
The key lat links both sources together is the “appid” <- a unique id from steam that represents the game. Since there are so many games and we don’t need all of the data from all of them, I wanted to try with only the top 100 games. So, the steps in order to get the data we need are:
- Request the top 100 games from the last 2 weeks from steamspy -> returns the
appid, name, and a variety of other information about the games.{'appid': 730, 'name': 'Counter-Strike: Global Offensive', 'developer': 'Valve', 'publisher': 'Valve', 'score_rank': '', 'positive': 7642084, 'negative': 1173003, 'userscore': 0, 'owners': '100,000,000 .. 200,000,000', 'average_forever': 31031, 'average_2weeks': 837, 'median_forever': 5370, 'median_2weeks': 326, 'price': '0', 'initialprice': '0', 'discount': '0', 'ccu': 1013936, 'languages': 'English, Czech, Danish, Dutch, Finnish, French, German, Hungarian, Italian, Japanese, Korean, Norwegian, Polish, Portuguese - Portugal, Portuguese - Brazil, Romanian, Russian, Simplified Chinese, Spanish - Spain, Swedish, Thai, Traditional Chinese, Turkish, Bulgarian, Ukrainian, Greek, Spanish - Latin America, Vietnamese, Indonesian', 'genre': 'Action, Free To Play', 'tags': {'FPS': 91172, 'Shooter': 65634, 'Multiplayer': 62536, 'Competitive': 53536, 'Action': 47634, 'Team-Based': 46549, 'e-sports': 43682, 'Tactical': 41468, 'First-Person': 39540, 'PvP': 34587, 'Online Co-Op': 34056, 'Co-op': 30342, 'Strategy': 30189, 'Military': 28762, 'War': 28060, 'Difficult': 26037, 'Trading': 25813, 'Realistic': 25497, 'Fast-Paced': 25369, 'Moddable': 6667}} - Loop through each
appidand submit a request to the Steam API for the reviews on the store page.
{'recommendationid': '199808702',
'author': {'steamid': '76561199829955378',
'num_games_owned': 0,
'num_reviews': 1,
'playtime_forever': 2335,
'playtime_last_two_weeks': 1300,
'playtime_at_review': 1348,
'last_played': 1753305341},
'language': 'english',
'review': 'yes',
'timestamp_created': 1752524911,
'timestamp_updated': 1752524911,
'voted_up': True,
'votes_up': 0,
'votes_funny': 0,
'weighted_vote_score': 0.5,
'comment_count': 0,
'steam_purchase': True,
'received_for_free': False,
'written_during_early_access': False,
'primarily_steam_deck': False}
In the example pasted here - from the most popular game “Counter Strike” - the review text is just “yes”. Voted_up = True is the boolean. …… Not a whooole lot to work with here. This is going to be challenging.
Note I later saw that the steamspy api does offer tags, genres, price, and score_rank data – a potential future source for predictive analytics.
Messy data solutions
The first issue I ran into was the absolute chaos of reviews about video games from internet strangers. There’s almost no filter at all. If there’s going to be any chance of relating information between what someone says and what they vote, then the information source has to at least be coherent.
To give you an idea of the reviews that exist on a random pull.
- “1” -> Voted down
- This game makes you wanna stub your face 10/10 -> Voted up
- yes -> Voted up
- emoji for thumbs up -> Voted up
- Harika -> Voted up
Now, with the reviews, the steam api also returns a useful field called “weighted vote score” - a “helpfullness” score they calculate based on the number of upvotes a review gets - and the likelihood that it’s just spam. A value between 0 to 1 where most reviews are rated 0.5 to start. Trying to require this score to be above 0.6 resulted in a 90% removal of all reviews downloaded on the first pass. 🪦🪦🪦
So, I set in motion another request from Steam that took a lot longer to process- this time only downloading reviews the met the following criteria:
- weighted_vote_score >= 0.51 ( at least a shot of not being spam )
- english letters and characters only (some people mark english but then write in different languages)
- review is at least more than 10 characters and has at least 2 words
By comparison - where the first random 1000 reviews took about 30 seconds to request, this filtered list took 10 minutes.
Conclusion: There’s a LOT of junk reviews on steam ( in hindsight this is obvious )
Here’s a view of the cleaned - non spammy - reviews:
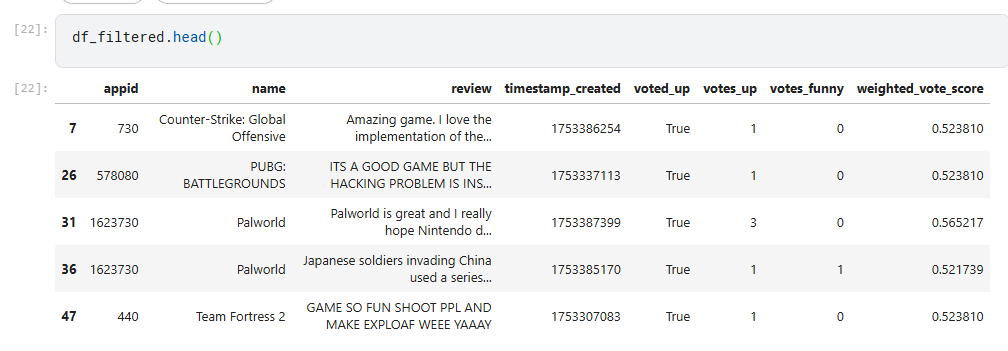
To be honest, I’m not even sure I totally solved the issue - and this is where my interest in fine tuning started to wear thin. If I ever come back to this data it will be to see if some more sophisticated model can just infer the sentiment for me.
Memory issues
The second issue I ran into with NLP was filling up the memory of the GPU / VM I was using on kaggle.
The steps to discover this included the core information about NLP.
For this project I used the huggingface transformers libraries. These convert text into numbers by having a huge dictionary of words already pre-assigned to some value. This is how NLP works - computers are just running CNN type math problems trying to optimize the combination of numbers that leads to the final goal. “Do a bunch of math to convert this sequence of numbers (that used to be words) into a final number close to my target.” This is a process called “tokenization”
Each model has its own tokenizer - for this project I used microsoft/deberta-v3-small on a recommendation.
Here’s what deberta-v3-small tokenizing looks like:
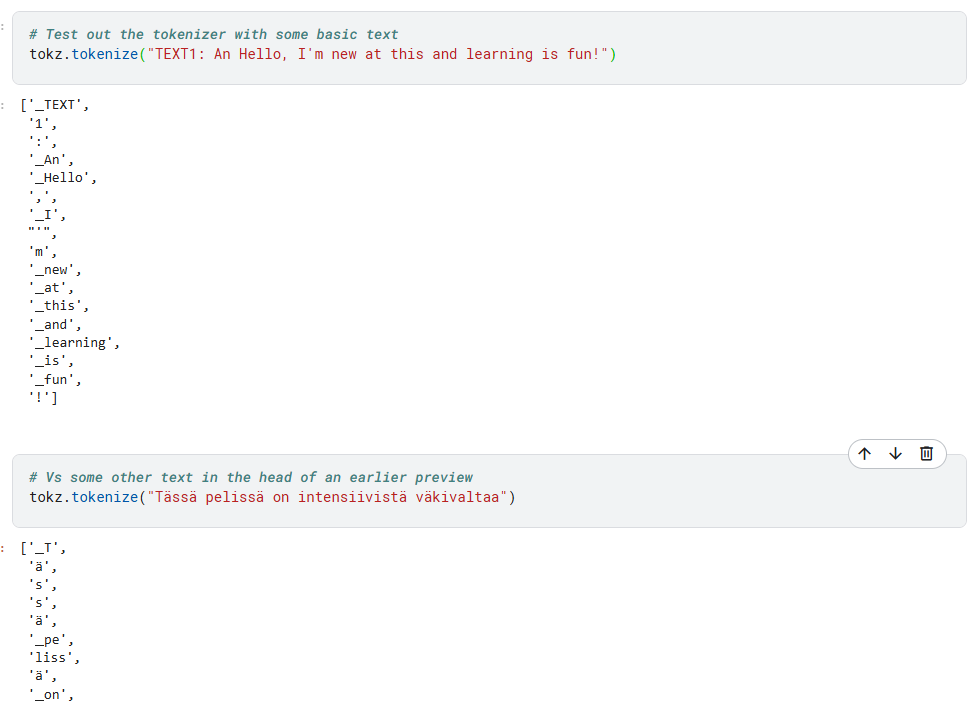
It does well with normal text, but cannot handle gibberish or foreign characters very well at all (it just converts them to characters)
Some reviews being thousands of characters long - this can turn into a memory overload issue, FAST. So - to clean up one more time, I decided to limit reviews to those with only 49 characters or less. Tokenizing short reviews is better than long ones.
('TEXT1: cs go forever', [1, 54453, 435, 294, 2285, 268, 424, 3629, 2])
A much smaller prediction subset
From this point - the dataset (basically a dataframe but the kind used for huggingface transformers) can get split into portions for training and.. trained!
The transformers terminology does get a bit confusing though - training and testing are for training, eval is for testing, and the parameter eval is for training testing. It’s a zoo. Someone should fix it.
Either way - the model ran with this smaller memory load and did - ~ok. The reviews were an unballanced (real) classification problem with many more upvotes than downvotes. The precision and recall statistics reflect this:
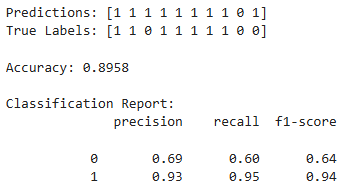
As a reminder (TP = true positive, FP = false positive, FN = false negative):
Precision = How many of the predicted class were actually part of that class.
1’s ex: TP / TP + FP = 93% -> When I predict an upvote, I’m right 93% of the time.
Recall = How many of the actual class did I catch?
0’s ex: TP / TP + FN = 60% -> I caught 60% of all the downvotes.
Accuracy = What fraction of the total predictions were correct?
ex: TP + TN / TP + TN + FP + FN = 89.6% -> The model is right 89.6% of the time
Accuracy is good for balanced datasets,
Precision is good for avoiding false alarms,
Recall is good for catching all positives.
The notebook
Here’s a link to the kaggle notebook where you too can see/experience the struggles in learning NLP :D
https://www.kaggle.com/code/morescope/nlp-steam